
Tính đến tuần này, 70 trong số 1.000 trang web hàng đầu thế giới đã chuyển sang chặn GPTBot. Hai tuần trước, OpenAI tiết lộ trình bot này đang được sử dụng để thu thập lượng thông tin khổng lồ từ internet nhằm đào tạo ChatGPT.
Originality.ai, một công ty kiểm tra nội dung để xem liệu nó có phải do AI tạo ra hay đạo văn hay không, đã tiến hành một phân tích cho thấy hơn 15% trong số 100 trang web phổ biến nhất đã quyết định chặn GPTBot trong hai tuần qua.
6 trang web lớn nhất hiện đang chặn bot là amazon.com (cùng với một số đối tác quốc tế), nytimes.com, cnn.com, wikihow.com, Shutterstock.com và quora.com. 100 trang web hàng đầu chặn GPTBot bao gồm Bloomberg.com, scribd.com và reuters.com, cũng như Insider.com và Businessinsider.com.
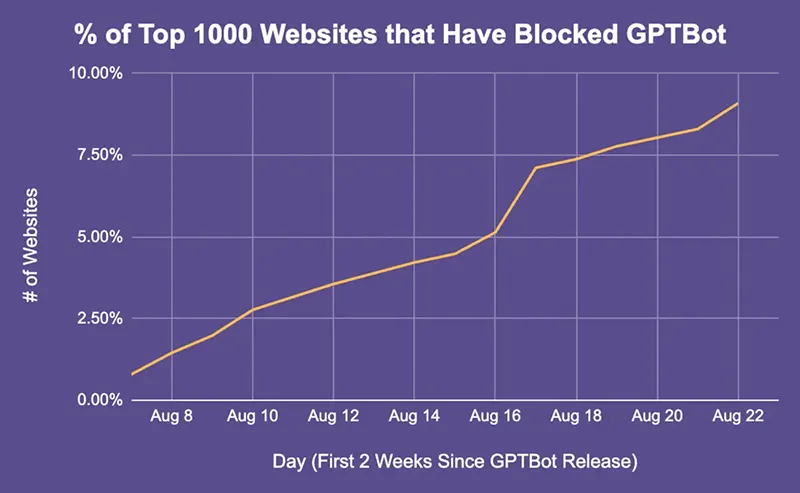
Trong số 1.000 trang web chặn bot hàng đầu có ikea.com, airbnb.com, nextdoor.com, nymag.com, theatlantic.com, axios.com, usmagazine.com, cô đơn.com và Coursera.org. Phân tích cho biết: “GPTBot đã ra mắt cách đây 14 ngày và tỷ lệ phần trăm trong số 1.000 trang web hàng đầu chặn nó đang tăng lên đều đặn”.
Cách các trang web này chặn GPTBot tương đối đơn giản, thậm chí thô sơ. Các trang web bao gồm một tệp có tên robots.txt và GPTBot đã được thêm vào danh sách "không cho phép". Robots.txt là một công cụ được tạo ra vào những năm 1990 nhằm ngăn chặn các trình thu thập dữ liệu web, chẳng hạn như trình thu thập thông tin tìm kiếm của Google hoặc Bing, trích xuất dữ liệu và thông tin từ một trang web.
Khi tiết lộ trình thu thập thông tin, OpenAI cho biết nó sẽ tuân theo robots.txt và GPTBot sẽ không thu thập dữ liệu các trang web triển khai nó. Phần lớn những gì có sẵn trên internet, đặc biệt là văn bản và hình ảnh, về mặt kỹ thuật đều có bản quyền. Các trình thu thập thông tin như GPTBot không yêu cầu sự cho phép, giấy phép hoặc trả tiền để sử dụng bất kỳ dữ liệu hoặc thông tin nào mà họ trích xuất.
Cách duy nhất để tránh chúng vào thời điểm này là thông qua robots.txt, mặc dù các công ty triển khai trình thu thập thông tin không bị ràng buộc về mặt pháp lý để nhận ra các hạn chế trong robots.txt.
Một số vụ kiện đã được thực hiện, cụ thể như tác giả Stephen King , sau khi biết sách của mình đã được sử dụng trong các bộ huấn luyện AI, cho biết ông đang nhìn về tương lai với một “niềm đam mê đáng sợ nhất định”. Về phần mình, OpenAI đã cố gắng che giấu rằng ChatGPT đã được đào tạo về bất kỳ tài liệu có bản quyền nào.


